

2024.12.07-2/2
从智能研究到企业应用的全栈AI实践指南,涵盖LLM开发、技术写作、智能客服和数据安全

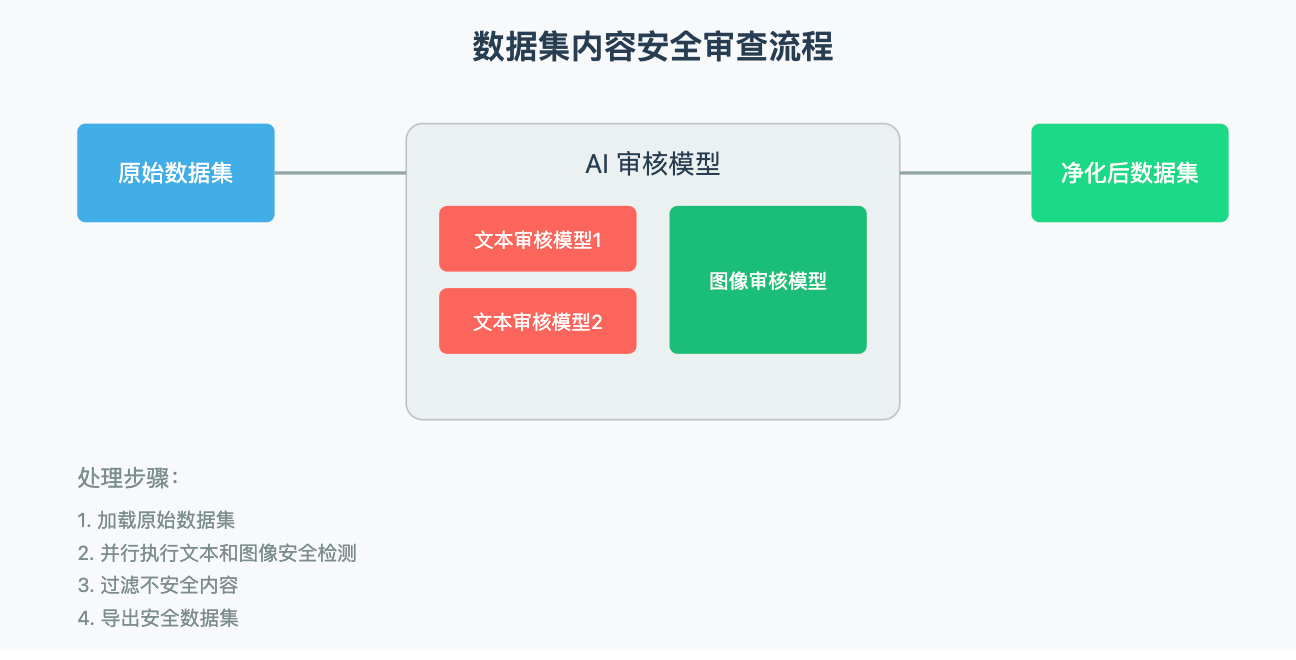
数据集清洗推荐:智能图文内容安全检测工具
「一个使用多重 AI 模型对数据集进行自动化内容审查的脚本,通过并行检测图片和文本的安全性,筛选并保留安全内容,最终输出经过净化的数据集」
数据处理设置:
- 使用了三个 AI 模型管道(pipeline):
- 两个用于文本分类的 NSFW 模型,检测文本是否安全 - 一个用于图像分类的 NSFW 模型,检测图像是否安全
核心函数 clean_dataset:
- 处理数据批次,检查图片和文本的安全性
- 检查四个图像列: image_columns = [ "image_quality_dev", "image_simplified_dev", "image_quality_sd", "image_simplified_sd"]
- 对每个图像和文本进行安全性评估,标记为安全或不安全
主要处理流程:
- 加载原始数据集 "image-preferences"
- 过滤确保所有必需的图像字段都存在
- 应用清洗函数处理数据
- 过滤掉所有被标记为不安全的内容(文本或图像)
- 移除临时的标记列
- 将处理后的数据集上传到 Hub,设置为私有

打造智能 Discord 客服: CAMEL 框架一键部署指南
「这是一个使用 CAMEL 框架开发的 Discord 客服机器人教程,通过整合大语言模型 (Qwen/Mistral)、向量数据库 (Qdrant)和网络爬虫 (Firecrawl),实现了一个能够进行知识检索和智能对话的自动客服系统」
主要组件
- CAMEL 框架:提供了构建 AI Agent 的基础设施
- Qwen/Mistral:作为对话引擎的大语言模型
- Firecrawl:用于网页内容抓取
- Qdrant:向量数据库,用于存储和检索知识
两个版本的实现
- 基础版本:直接使用语言模型回答问题
- 进阶版本:使用 Qdrant 向量数据库进行知识检索,然后再由模型生成回答
特色功能
- 支持长文本自动分段发送(处理 Discord 2000 字符限制)
- 集成了向量检索能力,可以基于相似度搜索相关内容
支持实时对话和知识库查询
技术写作进阶:打造个人影响力的实战指南
「通过持续输出高质量的原创内容、构建高效的创作流程、保持真诚的互动参与,从而在技术领域建立个人影响力和受众群体」
TL;DR
- 内容创作是一个良性循环,一篇内容可以衍生出多种形式的传播材料
- 重点是提供真实价值而不是硬销售
- 每个人的成长路径可能不同,需要找到适合自己的方式
1. 基于优秀作品进行创作
- 深入理解和参与他人的工作
- 真诚地为现有作品增添见解和价值
- 通过有意义的互动自然获得分享和关注
2. 保持持续输出
- 持续性比完美更重要
- 积极参与评论互动
- 要有耐心,不要期待立竿见影的效果
3. 提升文案写作能力
- 使用简洁清晰的语言,避免过度使用专业术语
- 追求大约六年级的阅读水平
- 可以使用 Hemingway App 等工具帮助简化写作
4. 建立语音转文字工作流
- 使用语音转文字工具(如 Superwhisper 或 VoicePal)捕捉想法
- 将日常对话和会议内容转化为内容素材
- 利用 AI 工具保持个人写作风格
5. 利用独特视角
- 分享独特的工作经验和见解
- 解答行业内常见困惑
- 把反复解决的问题转化为有价值的内容
6. 重视内容展示和传播
- 使用高质量的社交媒体卡片
- 合理安排发布时间
- 善用 X Threads 提高内容可见度
https://hamel.dev/blog/posts/audience/
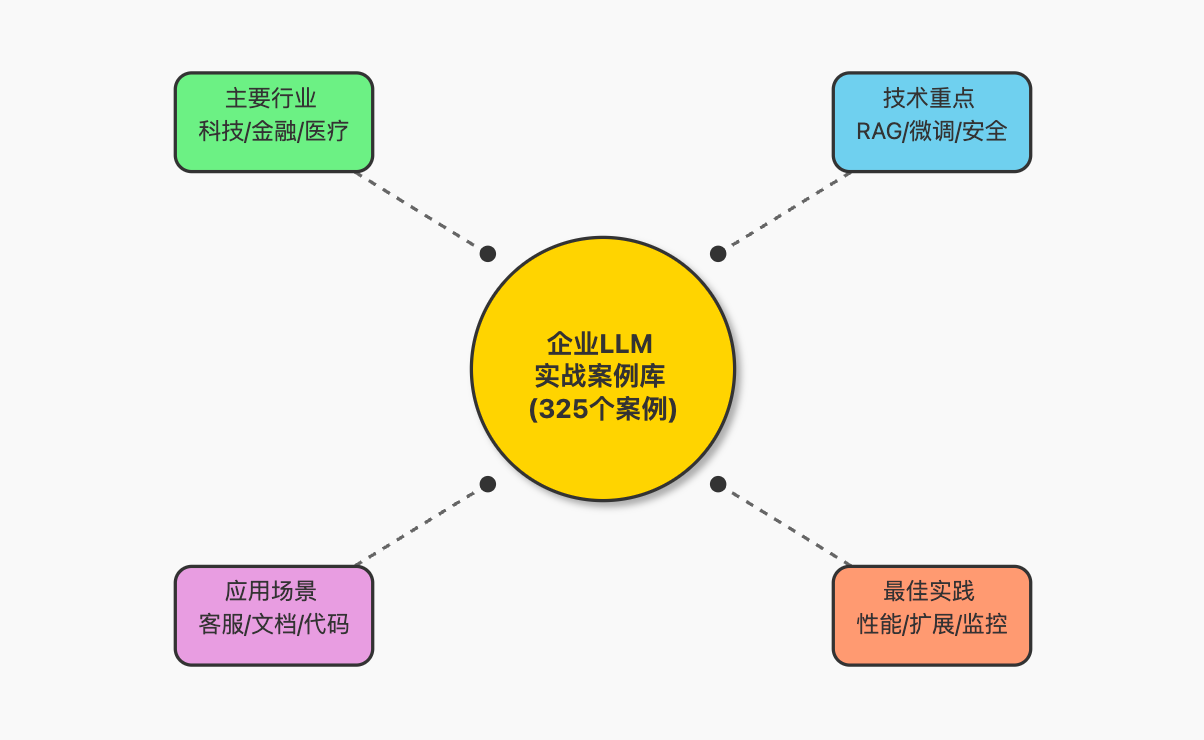
企业级 LLM 实战案例库:325 个真实应用与最佳实践
「 @zenml_io 最新推出的一个非常有价值的资源库,对于想要了解或实施 LLM 应用的组织来说,可以从这些真实案例中学习最佳实践和避免常见陷阱」
数据库特点:
- 收录了超过 325 个实际 LLM 应用案例
- 涵盖了从技术公司到传统企业的多个行业案例
- 每个案例都带有详细的技术标签,便于分类和检索
主要行业覆盖:
- 科技公司(如 Google、Microsoft、Amazon)
- 电商平台(如 Shopify、Doordash)
- 金融服务(如 Stripe、Morgan Stanley)
- 医疗健康(如 BenchSci)
- 教育机构(如 Harvard)
常见应用场景:
- 客户服务自动化
- 文档处理和分析
- 代码生成和辅助
- 搜索和推荐系统
- 内容生成和审核
核心技术关注点:
- RAG (检索增强生成)
- 提示工程(Prompt Engineering)
- 模型微调(Fine-tuning)
- 安全性和合规性
- 性能优化和扩展性
https://www.zenml.io/llmops-database
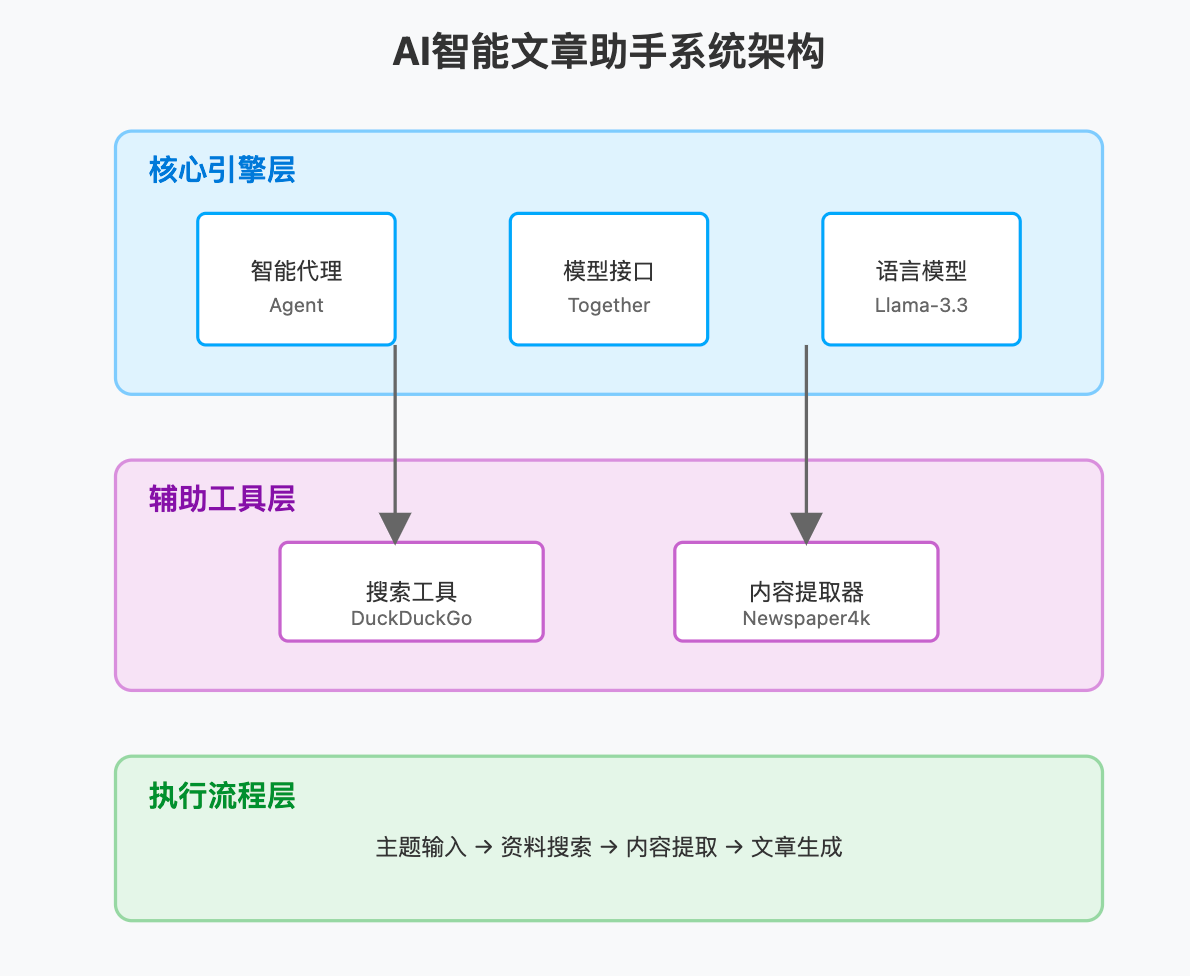
20 行代码搞定 AI 研究智能体 - phidata & Llama 3.3 70B
@phidatahq 核心组件层:
- Agent 类作为中央控制器
- Together 类提供模型接口
- Llama 3.3 70B 作为底层语言模型
- 整体采用模块化设计,便于扩展和维护
工具层:
- DuckDuckGo:负责信息检索
- Newspaper4k:负责文章内容提取
- 工具层采用插件式架构,可以灵活添加或移除工具
执行流程层:
- 采用管道式处理流程
- 每个步骤都有明确的输入输出
- 数据流向清晰,便于调试和监控
